General Overview
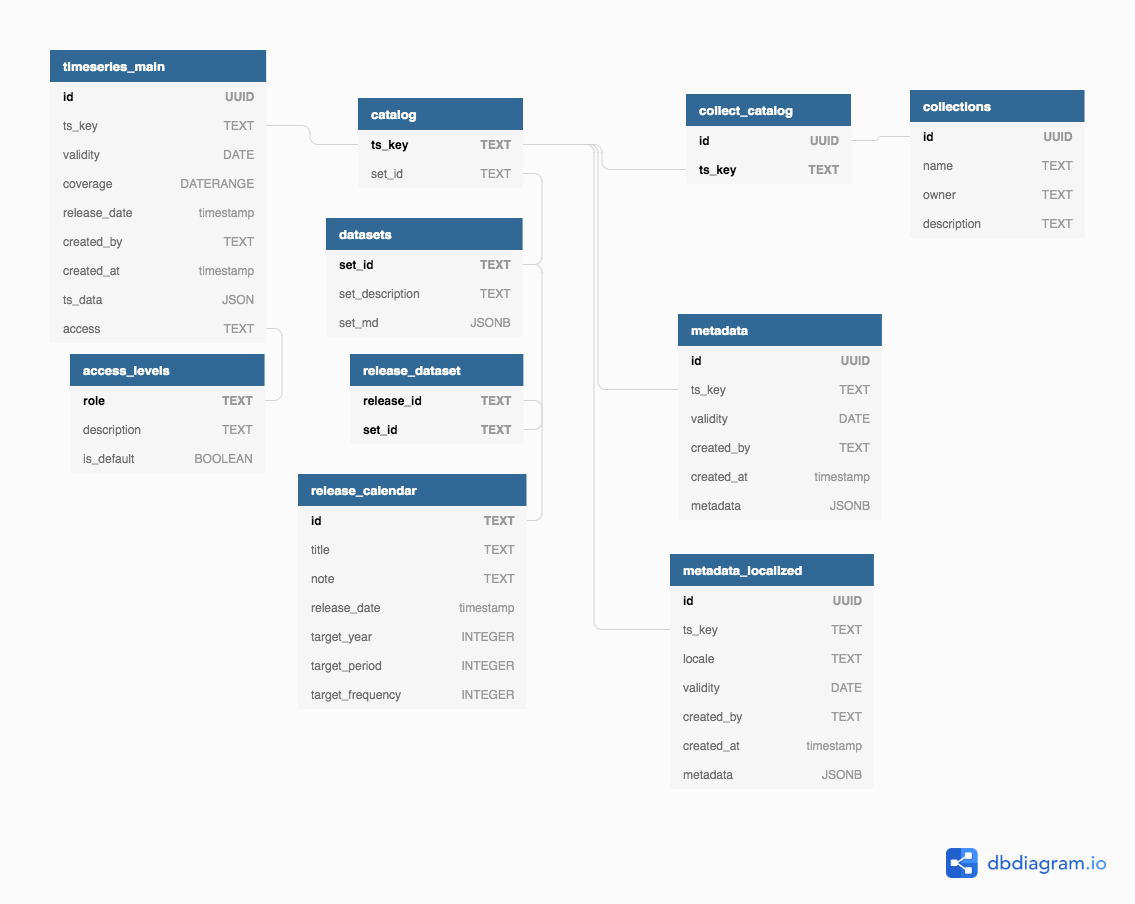
The vintages table is the main table that keeps all the different versions of a time series. The catalog table holds the stem of a time series identified by ts_key. These stems do not hold any observational values but provide links to datasets specific descriptions as well as time series specific meta information. This avoids redundancy and fosters searching keys by regular expressions in case the vintages table is hash partitioned. Collections allow users to create sets of time series identifiers (keys) in similar fashion as playlists in music apps. Tables with an md_ prefix store meta information at different levels. By having multiple tables the user can choose whether meta information needs to be versioned, too.
The following sections describe the actions behind standard write and read processes. Due to the fact that not only a time series itself is stored but versions of it as well as comprehensive data descriptions, multiple tables are affected.
Storing New Time Series
If an entirely new series is stored it belongs to the default dataset unless specified otherwise. Because a catalog entry for the stem does not exist yet, a new ts_key is inserted into the catalog.
Once a ts_key is created a first version is inserted into
the timeseries_main table. The first version is valid from the
current Sys.Date() until an open end.
Adding a New Vintage (Version) to an Existing Time Series
In case a ts_key already exists in the time series catalog it is NOT updated. This is major change compared to previous versions of {timeseriesdb} in which versions were not kept by default. With {timeseriesdb} > 1.0 the stem will not be modified. Instead a new version of the time series will be added to the timeseries_main table.
Internal Time Series Storage Format (ts json)
{timeseriesdb} stores time series themselves in a single json cell.
It does so to minimize the number of records because in economic
statistics (as opposed to IoT applications), users are looking for an
entire time series in a relatively large catalog (as opposed to few
series with many observations). Previous versions of {timeseriesdb}
relied on a PostgreSQL key value pair storage called hstore
which was replaced by the more common, DBMS agnostic json
format. The two main reasons for the switch from hstore to
json format was that order is not guaranteed in
hstore key value pairs and serialization of json is very
common and available for many libraries. By using JSON inside a RDBMS,
{timeseriesdb} useses the best of both worlds: JSON to minimize the
number of records and relations to provide comprehensive data
descriptions in multiple languages.
{
"frequency": null,
"time": ["2003-03-01", "2004-03-01", "2005-03-01", "2006-03-01", "2007-03-01", "2008-03-01", "2008-06-01", "2008-09-01", "2008-12-01", "2009-03-01", "2009-06-01", "2009-09-01", "2009-12-01", "2010-03-01", "2010-06-01", "2010-09-01", "2010-12-01", "2011-03-01", "2011-06-01", "2011-09-01", "2011-12-01", "2012-03-01", "2012-06-01", "2012-09-01", "2012-12-01", "2013-03-01", "2013-06-01", "2013-09-01", "2013-12-01", "2014-03-01", "2014-06-01", "2014-09-01", "2014-12-01", "2015-03-01", "2015-06-01", "2015-09-01", "2015-12-01", "2016-03-01", "2016-06-01", "2016-09-01", "2016-12-01", "2017-03-01", "2017-06-01", "2017-09-01", "2017-12-01", "2018-03-01", "2018-06-01", "2018-09-01", "2018-12-01", "2019-03-01", "2019-06-01", "2019-09-01", "2019-12-01", "2020-03-01"],
"value": [31.9, 36.4, 39.1, 48.2, 71.6, 100, 104, 97, 85.8, 76.7, 68.7, 64.9, 65.3, 75.1, 82.2, 84.8, 85.4, 98.1, 98.9, 97.1, 92.3, 100.6, 97.1, 100.5, 93, 98, 100.2, 105.3, 107, 114.4, 109.2, 111.9, 101.2, 101.9, 100.5, 94.9, 92.2, 105.452018790168, 106.4, 103.3, 100.3, 110.3, 103.7, 109.7, 108.9, 110.4, 113.8, 116.1, 118.5, 114.7, 124.9, 118, 115.8, 124.5]
}Access Management
{timeseriesdb}’s access management relies on the idea that users cannot directly issue SQL queries to the database. {timeseriesdb} uses SECURITY DEFINER functions which are executed as the owner of the function. The owner of the function is a privileged user that is allowed to do advanced stuff, but only within the scope of the function. This way access to the time series data can be managed at a very fine grained level.